
1.今年の予定、目標
今年の勉強する内容は去年と同じです。
今のところ、効果がしっかり出て来ているのでこれを続けます。
それぞれの節で何をやるのかはそれぞれの節で説明します。
2.映像作品としてのLevelの作成
2.1 去年のまとめと今年予定
去年は3D Gaussian Splatting、PCGの勉強、HDRIを使用したLevelの作成などをやりました。
それぞれについて追加情報や、考察などがあるのでそれをここにまとめます。
<3D Gaussian Splatting>
去年の検証では3D Gaussian SplattingはUE5で背景に使用すると歪みが生じるのでPhoto-Realisticな3Dを作成するための質は確保出来ない。と結論が出ました。
しかし以下に示したScanning Tokyo using Luma AI and Unreal Engine 5[1]を見ると
現実世界そっくりの映像がUE5で再現されています。
こういう奥行のある狭い街道を撮影した場合は、3D Gaussian Splattingの方がPhoto-Realisticな3Dを作成出来るのかもしれません。
後は、360度Cameraで撮影したのかもしれません。
後、Luma AIのGaussian Splatting for UE5にSample Dataが5つ位あるらしいです。
それが結構Photo-Realisticらしいです。
それのCheckもしてみます。
後、狭い部屋を撮影したら結構綺麗に出る可能性もあります。これも試してみます。
<PCGの勉強>
これは順調に成果が出ているので続けます。
完成した建物がもっとPhoto-Realになるためにはどうしたら良いのかの検証も行いたいと思います。
後、Condominium(マンション)がどんな最小単位を繰り返して建築されているのかの検証もやって行きます。
<HDRIを使用したLevelの作成>
Level Sequence上でAnimationの編集をする方法なんですが未だによく分かりません。
これについての調査も続けていこうと思っています。
それを踏まえて、今度の動画は路地裏に迷い込んだら死体が転がっていて、その死体が起き上がって襲い掛かって来るという物にします。
今年はこういう15秒程度のVFXの動画を3カ月に1本は出していこうと思います。
3.AIの勉強
AIの勉強に関しては、今までの続きをそのままやって行くだけです。ので特別なまとめは無いです。
続きをやっていきます。
3.1 Lecture 2の復習のまとめ
Lecture 2の勉強としてYouTubeの講義を見て、教科書のThe fastaiの第2章Productionを全部読み、更に副教材として用意されていたPractical Deep Learning for Codersの2章 Deploymentも読みました。
その結果分かったのは、このLecture 2ではLecture 1で作成したDeep LearningのModelをUIなどを追加して誰でも利用出来るWeb Appとして公開する事を方法を教えているという事です。
そしてLecture 2の宿題はLecture 1で作成したModelをWeb Appとして公開する事でした。
しかし教科書のThe fastaiの第2章Productionのやり方は、一寸古く、最新のWeb Serviceなどを利用したやり方を紹介しているのはYouTubeの講義とそれの解説をしている副教材のやり方でした。
つまりYouTubeの講義のやり方に沿ってWeb Appを作成するのが正しいやり方になります。
それでYouTubeの講義の復習をする事にしました。
2024-12-08のBlogからYouTubeの講義の復習をしています。
今週もこの続きをやります。
3.2 2024-12-22のBlogを復習する
で、YouTubeの講義の復習をどこまでやったのか全く覚えていないのでその復習からやります。
前半部分は単にFastAiを使用してDeep LearningのModelを作成する方法についての説明をしているだけです。Colabを使用して作成する手順をまとめ直していますが、このModelはOriginalな画像認識AIをLecture 1の宿題として既に作成しています。
のでそんなに重要ではないはずです。
次にこのModelをExportする方法が紹介されています。
これはKaggleのやり方しか書いてないです。Colabでどうやるのかの説明はまだないと書いてありました。
ExportしたModelはHugging Faceから利用出来るようにする必要があります。
そのためのFolderにこのExportしたModelを貼り付けました。
このFolderの位置はHugging FaceをGitHubからCloneした時のFolderです。
で、ここで一端Hugging Faceから離れてまたKaggleに戻っています。
今度はExportしたModelを利用してDeep LearningのPredictionを実行するための実装方法について解説しています。
2024-12-22のBlogではURLがどこでやってるのか分からない。とかなり焦っていました。
KaggleからExportしたFileを参照出来るのはどのFolderにそのFileをPasteする必要があるのかが不明だからでしょうか。
ああ、分かりました。
このテストを実装するのにKaggleをLocalで起動させる必要があるのかもしれないと書いてありました。
だからURLをみて焦っていたのか。
やっと前回、何を勉強していたのかが分かりました。
ここでまた問題発生です。
先程、Ubuntu上(つまりHugging FaceをDownloadしたFolder)のFileにあるdog.jpgをここから開いていました。
その後はLoad_Leaner()関数を使用してExportしたModelを使用したりしています。
この辺の実装方法に関しては特に疑問はありません。
そして更にGradioを使用したUIの作成にも取り掛かっていました。
Classify_image()関数を作成しています。
2024-12-22のBlogでは、これはGradioから使用出来る関数を作成する必要があるからだ。と書いてありましたが意味不明です。
GradioからはFastAIの関数を使用する事は出来ないから、この関数を作成する必要があるという事でしょうか?
以下の説明がありました。
GradioはTensor Valueを扱う事が出来ないのでTensorをFloatに変換する必要があります。
あ。
そういう事。
そして<Creating a Python script from your notebook with #|export>は来週やると書いて終わっていました。
その後に「3.2 今日の復習で分からなかったところ」という節があり、その言葉通り、分からなかったところがまとめられていました。

これは重要な疑問ですね。
Copilotに質問したら以下の方法でColabからHugging Faceを使う事が出来るよ。

と返って来ました。
うーん。
ExportしたModelを試すのはこれでもいいのかな?
いや、これだとHugging FaceにWebpageを作る事は出来ないです。
そうか、どうやってPC上にあるFileをColabから参照するのかの方法が分らないのか。
調べます。
Import data into Google Colaboratory [2]を見ると

ColabにImportしたいFileをGoogle Driveに上げて、ColabからGoogle DriveにAccessするのが一番早そうです。
久しぶりにStack Overflowを見ましたが、質問者に対する回答の意地悪ぶりは健在ですね。
こいつら本当にProgramming界の癌ですわ。
それは兎も角、ColabからLocalにあるFileをUploadする方法は分かりました。
後はKaggleからColabを使用する方法か。
うーん。
なんか違う事をやってる気がして来た。
もう一回Lectureを見直します。
ああ、分かりました。
DownloadしたModelをHugging FaceをDownloadしたFolderにSaveしたところまではあってるんですが、その後です。
KaggleからそのFolderに直接、Accessしています。
これか。
これのやり方が分からないのか。
そしてその後KaggleからGradioの実装をしています。

すると以下のWebpageが出来ています。

あ、これLocalhostじゃん。
そういう事か。
まだHugging FaceのWebは作成してなかったんだ。
この部分は納得。
でもLectureを見直してみると、やっぱりKaggleからUbuntuのFolderに直接Access出来るようになっていますね。
この設定をどうやるのかはまだ分かりません。
分からない部分はそれなりにありますが、とりあえず全体像を掴むため、先に進みます。
3.3 Lesson 2: Practical Deep Learning for Coders 2022 [3]の続きを復習する
実際は2024-09-23のBlogにまとめた内容を復習していきます。
<Creating a Python script from your notebook with #|export>
以下の#|exportについての解説です。

この印があるCodeだけが実装に必要なCodeだそうです。
そういう事なの?
いやここでやってる事は全く意味不明です。
以下の方法でNotebook2scriptをImportし

更に以下の方法でこのappの名前を指定します。

以下の返事が返ってきます。

ここまでは、#|exportが書かれているCodeをScriptとしてExportしたんだな。と分かります。
しかしここからが分かりません。
何とこのExportしたFile、VS CodeからApp.pyとして開けます。

なんで?
と思ったらその下に理由が説明されていました。
以下の設定があるので

うーん。
この設定でそうなるの?
よく分からん。
一応、TutorialのVideoの方で確認しますか。
うーん。
ここにまとめた以上の説明は無かったです。
App.pyをGradioにUpします。
TerminalからGit Commitと打つだけです。
Hugging Faceで確認すると以下のようになっていました。

うーん。
成程。
これで一応、Deep Learningを使用したWebsiteが完成しましたね。
残りは何をしているんでしょうか?
<Hugging Face deployed model>
Web上でテストしているだけです。
<How many epochs do you train for?>
ここはWeb Appとは関係ない話題でした。
<How to export and download your model in Google Colab>
おお、今度はColabでのExportのやり方を説明しています。
まあ非常に簡単なので2024-09-23のBlogの方を見て下さい。
<Getting Python, Jupyter notebooks, and fastai running on your local machine>
LocalでFastaiを走らせる方法を説明しています。
TutorialのVideoの方で確認したら、
やっぱりここでJupyterをLocalで走らせていました。
さっきのKaggleからExportしたFileを呼び出して動かしていたCodeはこのLocalで走らせているJupyterだったようです。
さっきのLocalhostのPageをもう一回見たら、以下に示した様にjupyterとしっかり書かれていました。

はい。
これで全部謎が解決しました。
<Comparing deployment platforms: Hugging Face, Gradio, Streamlit>
GradioとStramlitを比較してStramlitの方がFlexibleだとかそんな話だけでした。
とだけ書かれていました。
ここからは2024-10-06のBlogの内容になります。
<Hugging Face APIとJeremy's deployed website example – tinypets>
Hugging FaceのAPIについての説明です。
ここはHugging FaceではJavascriptが使用出来るので、Front Endの設定が自由に出来ますよ(Javascriptが使える事は前提)と言ってるだけです。
TutorialのVideoの方で確認しました。
Javascriptを使用して複数のImageを同時にUpload出来るようにWebsiteを改良した例が紹介されていました。
<Get to know your pet example by aabdalla>
これもJavascriptを使用した一例として紹介されています。
<Source code explanation>
使用したJavascriptの解説がされていました。
<GitHub Pages>
この最後の部分は2024-10-06のBlogではまだよく理解して無くて、この部分でやっとWebsiteが完成すると思っています。
ので何でGitHub Homepageに貼ってるの、Hugging FaceにWebsiteを作るんじゃななかったの。
って書いてありました。
このSiteは単に無料でHomepageが作成出来ますよ。と言う紹介でしょう。
無視します。
3.4 Lesson 2: Practical Deep Learning for Coders 2022 [3]の復習を終えた感想など
やっとLecture2の全体像が理解出来ました。
まずModelをCleanします。
その後でそのModelをExportします。
ExportしたFileを使用してLocalのJupyterからModelを実行出来るCodeを実装します。
更にGradioを使用したUIの作成の実装も追加します。
これが完成したらGitHubから別にDownloadしたHugging FaceのFileにExportします。
このHugging FaceをUPするとHugging FaceからこのModelを使用して画像分析出来るようになります。
その後はJavaScriptの説明とかです。
大体、こんな感じでした。
来週は実装をやるための計画を作成し、再来週から実装を開始する事にします。
4.Nvidia Omniverseの勉強
なんと今週はNvidiaが以下の発表を行いました。

これについてまとめる事にします。
4.1 NVIDIA CEO Jensen Huang Keynote at CES 2025 [4]を見る
一回、全部見たんですがあまりにもVolumeが多すぎてどこからまとめたら良いのか分かりません。
そうだ、AIにまとめてもらいます。
まずCopilotに聞きました。

うーん。
なんか抜けてる部分が沢山あるような。
Perplexityにも同じ質問をしました。

こっちも似たようなものか。
なんかここにまとめられている事ってそんなに重要じゃない気がします。
もう一回動画を見ながら自分でまとめる事にします。
まず最初に大事だと思うのがこの図です。
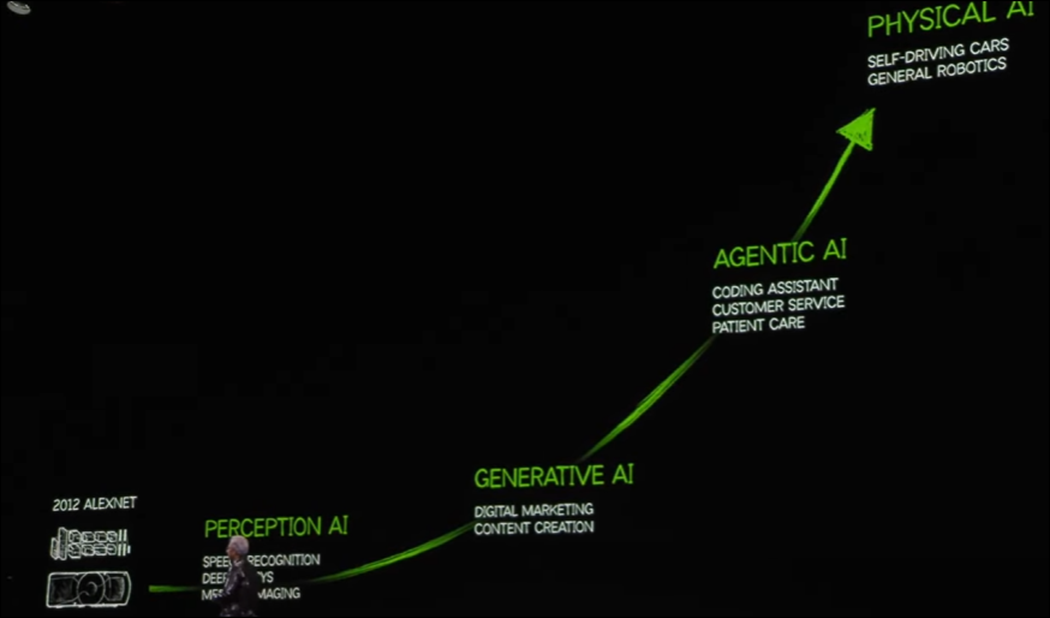
Exponentialに成長してる様が可視化されています。
さっき勉強していた画像認識のAIはここではPerception AIに属しているそうです。
その次に生成AIが来ます。
そしてAgentic AIとは人が作業をするのをAssist出来るAIだそうです。
そして最後にRobotがあります。
これこそがAIの発展の何たるかを示す世界地図だと思うんです。
こういうのが大切だという事はAIにはまだ理解出来ないみたいですね。
今度はAIを利用したRenderingがGPUの画像生成に革命をもたらしている件について話しています。
ここは最新のDLSSについての解説でした。
Ray Tracingを用いてPixel2つだけ計算したら残りの3300万個のPixelはAIが勝手に予測してくれるそうです。
凄い。
あれ、次のセリフではPixel200万個だけ計算したら、と言っています。どっちが正しいんでしょうか?
RTX50 Seriesの解説です。
Shader LanguageからNeural Networkが使用出来るようになったそうです。
もっと具体的に言うとMaterialの生成やTextureの圧縮にAIが使用できるようになったそうです。
これって結構凄いと思うんですがどうなんでしょう。
でこれですね。

RTX4090と同程度の機能を持つRTX5070が$549で買えてしまう訳です。
勿論、これはNvidiaが〇兆円かけて開発したAIが搭載されているからこの程度のGPUでもRTX4090と同程度の機能を発揮できる訳です。
〇兆円かけてAIを開発しても儲からないとか寝言言ってる連中は、この事実を噛みしめて咀嚼してほしいですね。
こんなの儲かるに決まってるし、この分野に資本をつぎ込まなかったらこれからの競争に勝ち残る事は出来ないじゃないですか。
今度はAIの性能と学習に使用するGPUの規模の関係についてのお話です。

AIの学習に巨大なData Centerが必要なのはこの最初のPre-Training Scalingの話です。
残りのPost-TrainingやTest-Timeが何を指してるのかよく分からなかったです。
一応、Jensen Huang氏の説明ではPost-TrainingはAIの答えを人間の専門家がCheckする段階、Test-Timeは同じ結果を出すのにどれだけ計算量を減らせるのかの段階、
だそうです。
こんなのにもScalingがあるのか。初耳です。
今度はBlack WellによるData Centerのお話です。
ここはまあ凄く儲かってます。て結論でしょうね。話を聞いていると。
Agentic AIのTesting Time Scalingの図が紹介されていました。

これは後でNvidiaのHomepageでしっかり勉強します。
Agentic AIの潜在的な顧客はSoftware Engineerで、彼らが仕事でProgrammingを書く時のAdvisor的な存在になるそうです。
それは理解出来たのですが、そこで表示されている以下の図との関係がよく分からないです。

ここの説明は最後まで理解出来なかったです。
次は以下の解説でした。

これは興味がないのでSkipします。
次はNvidiaのAI Systemを構成するために強力している会社の紹介です。

日本の会社は一個も無いですね。
この後またAgentic AIの説明がありました。今度はもっと詳しく説明していました。
これはあんまり心に響きません。
最後にこのAgentic AIはWindows PCのWSL2を使用する事で全てのWindow PCで動くようになるらしいです。
うーん。
値段が知りたいですね。
今度はAIで3D Modelを作成してそれをArtistが配置し、その風景の写真を撮り、その写真からAIがImageを生成する話です。

これもさっきのAgentic AIがやってくれるそうです。
うーん。
これは革命的な技術でしょう。
最後にとんでもなく凄い話になりましたね。
これが実現したらPhotoshopとか要らなし、下手したらUE5やBlenderも要らなくなるかもしれません。Houdiniの勉強も無駄になるかもしれません。
恐ろしい。
今度はPhysical AIについてです。

ここでWorld Foundation Modelについての説明がありました。
これが空間、重力、遠心力、原因と結果などの世界を構成するものを表すModelだそうです。
例として述べていたのが、ボールを塀の向こうに投げてボールが見えなくなっても塀の裏側にはボールがしっかり存在している。とかだそうです。
確かにこういうのはAIがImageを生成した時に忘れそうです。
ここから生成されるものって現実の3D空間で適用出来るものになるって事なんでしょうか?
そしてこのWorld Foundation Modelの名前がCosmosだそうです。
ここからCosmosの説明に入ります。
まず以下の図が表示されましたが

あんまり深い説明はありませんでした。
その後、Textから3D空間を生成していました。

凄い。
こんなのが出てきたら今までのように一々3D Modelなんて作ってる必要なくなりますね。
Robotの学習において、視覚だけが必要な場合はこれで完璧でしょうね。
ネジのような複雑な形状のものやパンのようなソフトなものもこれで生成出来るんでしょうか?
さっきはTextから全部生成していましたが、次の説明ではOmniverseで生成したのをCosmosにPassしていました。

全部Textureで生成する事もあらかじめ3D空間を作成してそれを元にCosmosで生成する事も出来るみたいです。
あ、これはあれだ。最初のころに説明していたAIを使用したRenderingだ。
うーん。でもBallを転がしたりした時の物理計算とかもやってくれそうですね。
そういうのをまとめたのがCosmosって事なんでしょうか?
一寸Cosmosの実態が見えて来ました。
もっと説明を聞いたら更に理解が深まりました。
要は強化学習に必要な一寸だけ変化した環境を生成するんです。
後、3Dの世界を作成するための学習はしてないそうです。Cosmosは我々の世界がどんな風に構成されどんな仕組みで動いているのかを学習しているそうです。
でRobotに必要な3つのComputerの話になりました。

DGXはData CenterでAIの学習に使うやつだと思います。
AGXが何なのかが分かりません。
RobotについてるComputerの事でしょうか?
今度はこれらの技術の実際の応用について解説しています。
まず倉庫の設計にOmniverseが使用された例が紹介されました。
次の例は車です。

自動運転の学習に使用するんでしょうか?
ここでToyotaが紹介されています。
で次世代のAGXを生成するための共同開発を始めるって言ってるように聞こえるんですが、どうなんでしょう。
Captionで確認したらAGXとは出て来ませんでした。
AGXって一台一台の車に付くんでしょう。
これってとんでもない売上になるんじゃないでしょうか?
で車に積むほうのAIのProcessorを紹介していました。

更に車用のOSも紹介していました。

今度はRobotの話です。

うーん。
これが最後の話ですかね。
人間型のRobotはImitation Informationが少ないと言っていました。
Imitation Informationて、学習に使用する人間が動いている映像の事でしょうか。
それなら少ないとは思えないですが。
動画で説明していましたが、やっぱり学習用に使用するDataの事でした。
動画を見た感じではまだ人型Robotは解決しないといけない問題が沢山ありそうです。
今度はDjx1の話です。

これはDjx1では無くてDix1の機能を持つNvidiaが作成した最新のAI Computerだそうです。
NvidiaのAI関連の全てがこのAI Computer内で動くそうです。
Localでやりたい事がある企業向けの製品ですね。
AIのRaspberry Piみたいなものでしょうか。
名前はDigitと言うのかな。
以上でした。
4.2 NVIDIA CEO Jensen Huang Keynote at CES 2025 [4]を見た感想
大体どんな話をしているのか分かりました。
まずCopilotとPerplexityのSummaryを見直してみます。

AI Foundation Modelが何を指しているのか分からなかったんですが、AI Agentの事みたいです。
かなり綺麗に内容がまとめられていて結構凄いと思いました。
10点満点で9点以上はありますね。
PerplexityのSummaryです。

CosmosはHardwareじゃないです。
更に言うとNIMやBlueprintはAI Agentの一部でSoftware EngineerがProgrammingをするのをAssistするのが主の目的です。Gamingのためではないです。
ToyotaとAGXを開発すると断言しています。
Citationもあるみたいですね。
この辺はPerplexityの強みですね。
うーん。
Copilotには無いSearchした結果を反映している点は評価出来ますが、内容に間違いが多すぎます。
10点満点で5~6点ですね。
こういう風に比較するとCopilotが意外と優れている事が分かります。
発表を聞いた感想ですが、まあCosmosには驚きましたがRobotの研究はまだまだ始まったばかりで、特にOmniverse+Cosmosの部分はRTXが一台あれば大企業の研究とも渡り合えそうです。
この辺に集中して勉強していきます。
5.Gaeaの勉強
5.1 IllustrationをAIでAnimationにする
今のAIの技術なら以下のIllustrationをAnimationにする事も可能な気がします。

調べてみます。
Copilotに聞きました。

この中だとToonCrafterが使用出来そうです。
なんか最近Copilotの質が落ちている気がします。
Perplexityでも聞いてみます。
Animakerばかり進めて来ます。
うーん。
日本語で検索してみます。
Meta社のAnimated Drawingsがお勧めに出て来ました。
うーん。
子供向けって感じがします。
Animate Anyoneもありました。
これは凄い。
Animate Anyone - Only 1 Image needed!!!!というTutorialもありました。

一寸見たら結構難しそうです。GitHubのCodeから一々セットしています。
Comment欄を見ると動かないとのCommentが沢山書かれていました。
どうしようかな。
これを勉強しますか。
画像が動き出す!…驚きのAI技術! Moore-AnimateAnyoneとMagicAnimateの使い方を紹介! AI TikToker GoogleColab AnimateAnyoneに別なSoftの紹介がありました。

ーん。
軽く見ただけですがAIはAIで色々問題ありますな。
Animate AnyoneはColabにあるMoore_AnimateAnyone_colab.ipynbを試してみたんですが、Errorになって動きませんでした。
![]()
だそうです。
YouTubeでも去年に大騒ぎしてそれ以降音沙汰無しです。
もっと簡単に出来るのはないんでしょうか?
Viggle AIというのがありました。

Tutorialを探したら、最近Websiteの形式が変わったらしくて、Discordのやり方しか説明していません。
How To Use Viggle AI For Beginners | Viggle AI Step-By-Step Tutorial 2025がWebでのやり方を説明していました。
これ見ると全身のImageが必要みたいです。
perchance.orgというAIのSiteで全身絵を生成してくれるそうです。
試してみます。
似たImageにするために以下のPromptを入れました。
a woman in school uniform. whole body, standing next to blackboard, make v-sign, (Your Name art style:1.3), Red hair, pony-tail
結果です。

え。
これAIが生成したの?
凄すぎない。
もっとPromptに拘ったらもっとすごいのが出来るの?
このイラストを利用してViggle AIで動きをつけます。
何故かShort Videoになってしまいました。
設定を確認します。
分からんけどUnlistになってるから良いか。
後、今気が付いたけど、BGMがついたままになっていました。
今度はBackgroundをGreenにして作成してみます。
これならIllustrationの代わりに使用出来るかも。
6.Houdiniの勉強
あまりにもAIの生成したAnimationが凄いので予定を変更する事にします。
今まではAIの勉強は一週間に一回でしたが、これからは2/Weekにする事にします。
でどれを削るのかですがVFXの勉強はHoudiniの勉強ですので、これは今のVEX Isn't Scaryの勉強が終わったらやる事にします。
6.1 VEX Isn't Scary Project - Part 1: Line Generation [5]を実装する
<Intro>
特になし
<Coding>
新しいProjectを作成してGeometryノードを配置しました。

GeometryノードはVEX_Projectと名付けました。
Geometryノードを開いてAttribute Wrangleノードを追加します。

Run Overの値をDetail(only once)に変更します。

以下のCodeを追加しました。

ここで使用するVariableを宣言しました。
更にFor Loopを追加しました。

以下の実装を追加しました。

そしてlineStartの値をAssignする方法、つまりSet()関数を使用する必要も確認しました。
結果です。

<Degrees>
HoudiniはDefaultでは角度の単位はDegreeではなくRadianなのでCodeを直します。

更にLineのEndにもPointを追加するためのCodeを実装します。

結果です。

<Add Prim>
作成したPointを繋げてLineを作成します。
Addprim()関数を追加してLineを作成しています。

結果です。

出来ました。
<Code>
作成したLineがCircle内にぴったし一致する事を示すTestをやりました。

Linesの値を46にしました。

お、Tutorialで言っていた通り、Lineの一部が消えています。
以下のLineの

180を180.0に変更しました。
結果です。

直りました。
以上です。
7.AIの勉強2
ここはAIの勉強に使用します。
これだけAIが発展してくると、もうHoudiniの勉強をしてもあまりメリットは無い気がします。
で、何を勉強するのかですが、
- AIの勉強
- Omniverseの勉強
を勉強します。
つまり2馬力でAIの勉強をします。
しかし他の事を勉強しても良い事にします。
例えば今週のGaeaでやったAIのSiteをもっと使用してみる。とかです。
7.1 「Gaeaの勉強」でやったAIによる動画の作成の続きをやる
以下の講義の動画を見つけたのでこれを使用してViggle AIで講義しているAnimationを生成します。

結果です。
凄い。
ここで終わったんですが、あまりにも結果が凄いので次の日も試してみました。
まず以下のIllustrationで試してみました。

なんとどんでもない化け物動画が生成されました。
気持ち悪くてすぐに消してしまいました。
どうも私の描いたIllustrationのそれぞれの人体のPartsをAIは単なる模様と認識したらしく、とんでもない結果になりました。
今度は以下の画像で試しました。

結果です。

何とPonytailが無くなってしまいました。
あれ。
後なんか手が大きい過ぎる気がします。
うーん。
AIが生成したIllustrationの方が良い結果が出るみたいです。
今度は一分ぐらいの長さで講義している動画が見つからないのでUE5でMannequinにIdlingの動作をさせてそれを撮影し、Sourceの動画として使用してみます。
結果です。
肩幅がとんでもない事になっている。
AI Illustration Generatorで以下の新しいIllustrationを生成して

試してみましたが

肩幅がとんでもない事になりました。
あれ?
昨日生成したVideoは正面から見ても普通の肩幅をしています。

うーん。
もしかしたらSource用のVideoに使用したMannequinの肩幅が広いのが原因?

じゃ代わりにSKM_Quinnを使用して動作を作成します。
あれ?
QuinnにMannequinのAnimationを追加出来ません。
そうなの。
UE4 Marketplace Animation Packs in UnrealEngine 5 (IK Retargeter) にやり方が載ってるみたいです。

今は試している時間はないです。
SKM_Quinn用のAnimationで歩いているのがありました。

これで試してみます。

やっぱり凄い肩幅になってる。
何で?
ここで一日に使用出来るMaxを超えてしまいました。
8.DirectX12の勉強
今週は別な用事が入ってDirectX12を勉強する時間が無くなってしまったんですが、出来るだけやる事にします。
8.1 Lötwig Fusel氏のD3D12 Beginners Tutorial [D3D12Ez]を勉強する
8.1.1 Resource State | D3D12 Beginners Tutorial [D3D12Ez] [6]の最初の10分を実装する
今週からResource Stateについて勉強します。
<Intro>
特になし。
<Explanation>
なんかずっとOptimizationについて語っています。
でこういうOptimizationを実行するためにはResourceがどんな風に使用されるのかについてのMetaな情報を教える必要があると。
ずっと話を聞いているとどうもResource Stateで画面に表示するImageの話のようです。
<Memory Barriers>
やっと実装が始まりました。
まずWindow.h Fileの以下の場所にBeginFrame()関数を追加しました。

更にEnd Frame()関数も追加しました。

ここでこの節は終わりです。
今週は時間がないのでここまでとします。
8.2 「DirectX 12の魔導書」を勉強する
8.2.1 前回の勉強の復習をする
前回何をやったのか忘れてしまっています。2024-12-22のBlogを見て復習します。
Blogを全部読み直しました。
「5.8 Root SignatureにSlotとTextureの関連を記述する」を全部読んで内容をまとめていました。
ここではRoot Signatureに新しく追加したTextureの情報を追加しているようです。
8.2.1「 5.8.1 Descriptor Tableとは」を勉強する
DirectX12ではDescriptor TableはRoot ParameterというStrictを使用して表すそうです。
この節では以下のように前に作成したRootSignatureにRoot Parameterをセットする方法を紹介しているだけでした。

実際のRoot Parameterは次の節で作成するみたいです。
ちなみにこの実装のNumParametersは追加するRoot Parameterの数を指定しているのだそうです。
今回はRoot Parameterは一個だけ追加するので1がセットされています。
以上です。
9.まとめと感想
なし
10.参照(Reference)
[1] jeff wilkins jr. (2024, January 12). Scanning Tokyo using Luma AI and Unreal Engine 5 [Video]. YouTube. https://www.youtube.com/watch?v=xUh4RnFkbPw
[2] Import data into Google Colaboratory. (n.d.). Stack Overflow. https://stackoverflow.com/questions/46986398/import-data-into-google-colaboratory
[3] Jeremy Howard. (2022, July 21). Lesson 2: Practical Deep Learning for Coders 2022 [Video]. YouTube. https://www.youtube.com/watch?v=F4tvM4Vb3A0
[4] NVIDIA. (2025, January 7). NVIDIA CEO Jensen Huang keynote at CES 2025 [Video]. YouTube. https://www.youtube.com/watch?v=k82RwXqZHY8
[5] Nine Between. (2021, February 10). VEX isn’t scary Project - Part 1: Line Generation [Video]. YouTube. https://www.youtube.com/watch?v=XDFELm4bcFk
[6] Lötwig Fusel. (2023, July 8). Resource State | D3D12 Beginners Tutorial [D3D12EZ] [Video]. YouTube. https://www.youtube.com/watch?v=yWg0TVahQzI