
1. 今週の予定
以下の内容を勉強します。
2. 映像作品としてのLevelの作成
2.1 PCGの勉強
2.1.1 Get Started With PCG 5.4 By Creating a Full Building | UE 5.4 P1 [1]の続きを実装する
先週勉強した内容を実装します。
<Loop Counter Subgraph>
BPのVariablesにFloorsを追加しました。

Get Actor Propertyノードを配置します。

Property NameにFloorsをセットします。

次にGet Actor Dataノードを配置します。

ModeにGet Single Pointをセットしました。

以下のようになりました。

更に以下の実装を追加しました。

結果です。

Floorsの値は4に指定しています。
更に以下の実装を追加します。

Spline SamplerノードのNum SamplerにはFloorsの値をPassします。
更にUnboundをEnableしました。

更にScale Methodの値をAbsoluteに変更しました。

この辺は何をやっているのかよく分かりません。
実装が終わってから考察します。
以下のようになりました。

Spline Samplerノードを選択してAを押し

このNodeにあるDataをSpreadsheetに表示します。

それぞれのPointを別々のPoint Dataに分別するためにAttribute Partitionノードを追加します。

Attribute PartitionノードのIndex[0]の値を$Indexに変更します。

これでそれぞれのPointsが別々のPoint Dataに分配されました。

次にGet Attribute From Point Indexノードを追加しました。

Get Attribute From Point Indexノードを選択してAを押してSpreadsheetを表示します。

以下のようにPCG Attribute Setだけが表示されました。

今までの実装を一個のSubgraphノードにまとめました。

新しいNamed Rerouteノードを追加しました。

新しいNamed Rerouteノードの名前はFloor Loopsにしました。
以上です。
これを使って何をするのかがまだよく分からないです。
来週の分までやってからそれぞれの実装の意味を分析します。
2.2 動画の作成ための勉強
2.2.1 Control Rigを使用してLevel SequenceからAnimationを編集する方法を調査
以下の動画でどうやってLevel Sequence内でAnimationの調整をするのかが解説されていました。

一分以下の動画です。見てみます。
うーん。
多分。これで出来るでしょう。
この動画の内容を以下にまとめます。
2.2.2 How to Edit Mannequin and/or Metahuman Animations directly in Sequencer [2]を勉強する
まずLevel Sequenceを開きます。

次にこのSequenceにAnimationを変化させたいActorを追加します。

これ見るとBPを追加していますね。私のDragonはBPだったか覚えていません。
後で確認します。
追加すると以下のようにControl Rigが表示されます。

これを消してしまいます。
えー。
Control Rigを使用しないの?
そしてBodyに直接、使用するAnimationを追加しました。

次にこのAnimationをControl RigにBakeするそうです。

Bake Control Rigを選択し使用するControl Rigをここから選択しています。
すると以下のように

指定したAnimationのMotionがLevel Sequence上に逐一表示されます。

凄いけど。
逆IKとかないとAnimationの操作出来ない気がします。
最後に編集したAnimationをBakeして新しいAnimation Sequenceを作成する方法を説明しています。
BodyからBake Animation Sequenceを選択し

以下のWindowが表示されるので

Saveする場所とAnimation Sequenceの名前を指定します。
作成した新しいAnimation Sequenceが開き表示されてます。

以上でした。
2.2.3 How to Edit Mannequin and/or Metahuman Animations directly in Sequencer [2]を勉強した感想
こんなのとても実用的な方法じゃないでしょう。

足の位置を地面と一致させてこれを直したいだけなんですが。
2.2.4 先週作成した映像を一般に公開する
前に作成した動画で既に完成しています。
題だけ直して公開する事にします。
A young dragon who failed to breathe fire.
以下の説明を追加します。
3D Gaussian Splattingは約束された次世代の技術と思われています。しかしUE5内で限って言えば3D Gaussian Splattingで生成された背景は歪んでしまいます。まるでピントがずれたカメラで素人が撮影したような映像になってしまいます。
それに対してHDRIとLandscape(Gaea2を使用して作成)したこの映像にはそのような欠点は存在しません。
私はUE5で映像を制作するなら3D Gaussian Splattingを使用するよりも、この手法の方が優れていると思います。
英語に直します。
3D Gaussian Splatting is considered a promised next-generation technology. However, within UE5, the background generated by 3D Gaussian Splatting is distorted. It looks as if it was shot by an amateur with an out-of-focus camera.
In contrast, this video, created with HDRI and Landscape (created using Gaea2), has no such drawbacks.
I think this method is superior to using 3D Gaussian Splatting when creating a video in UE5.
Deep Lで翻訳しました。
一読しましたが翻訳に問題がありそうなところは見つからなかったです。
これを説明文に使用します。
公開しました。
2.2.5 HDRIと3D Gaussian Splattingの比較
HDRIと3D Gaussian Splattingを比較したVideoを作成します。
出来ました。
どう見てもGaussian Splattingで作成した背景は歪んでいます。
公開するのは説明文を考えてからにします。
来週まで待ってから公開する事にします。
3. AIの勉強
3.1 先週の復習
先週は教科書の「02_production.ipynb」を読み直したんでした。
今週はLectureの内容を復習します。
3.2 Lesson 2: Practical Deep Learning for Coders 2022 [3]を勉強した内容を復習する
<<Putting models into production>>
この節のまとめからAppの制作が始まっています。
Blogではこの部分の内容はあまりうまくまとめてはなかったです。
読んでて?となる箇所が沢山ありました。
それでも何とか読み進めると以下の内容が書かれている事が分かりました。
- 熊のぬいぐるみを識別するCodeを紹介
- Cleanについて
あ、分かった。これ。DataをCleanする必要がある事を説明したんです。しかしその説明とは裏腹にDataをCleanしないで、集めたDataをそのまま使用してDeep LearningのTrainingを始めたので??となってしまったんです。
今ならDataをCleanするのはTrainした後だという事を知っているので全く不思議ではないですが、このBlogを書いたときはかなり混乱して???となっていました。
一応、Lesson 2: Practical Deep Learning for Coders 2022 [3]を見て確認します。
見ました。
ああ、成程。
まずProductionの意味を真に理解してはいなかったです。
Productionって製品化って意味でした。
前回のLectureではModelまで作成したので、今回のLectureはそのModelを使用して製品まで作成するって言っていました。
そしてその最初のStepがDataをCleanする事に繋がる訳です。
はい。
理解出来ました。
<<Gathering images with the Bing/DuckDuckGo>>
Blogにまとめた内容を読む限りではここの内容は前のLectureでやったModelの作成を繰り返しているだけです。
一応Lectureを見て確認します。
はい。
教科書にはBingのSDKを使用してBingからDataを集めています。
しかしBingのSDKを使用するためにはSDK keyを取得する必要があり、それが結構大変です。
なのでそういう事をする必要のないDuckDuckGoを使用してDataを集める事にした。
と説明していました。
成程。
教科書を読んだ今ならこの説明は100%納得です。しかし前回のLectureしか見てなかったのでこの説明は聞き逃してしまっていました。
その結果、何で前のLectureでやったDuckDuckGoからDataを集める方法をもう一回勉強してるの?
となって???となってしまったんです。
更にここではTeddy BearとGrizzly BearやBlack Bearの識別が出来るAIを作成しています。
これもLectureを見た時は何で今更熊の識別をするの?と
これは単なる例で使用しているとまで解説していました。
あー。
Lectureを真に理解するにはLectureを見る前に教科書を読む必要があったって事でした。
ここでこの週のBlogは終わっていました。
ここでも製品化(Production)に関係する節の内容だけまとめていきます。
<<Cleaning the data that we gathered by training a model>>
Blogでは「DataをCleanする前にTrainするって言っています。それだけでした。」と言っています。
本当でしょうか?
一応確認します。
本当にそれだけでした。
<<Explaining various resizing methods>>
一応、Dataを集める方法など前のLectureで勉強した内容を軽く復習しています。
その過程でDataであるImageのSizeを統一するために集めたImageのSizeを変更するんですが、そのImageを変更する方法が幾つもあるのでそれらについて解説しています。
これは単に教科書の内容に沿って説明していたら、ImageのSizeを変更する方法が書かれていたので、それについて補足の説明をしているだけって感じでした。
まあ製品化に当たってImageのSizeを変更する方法の重要度は低いです。
Cropping、SquishingそしてPadという方法が紹介されています。
ここまで理解すると、この手法に対しての建設的な批判を述べる事も可能になります。
人間が熊の種類を認識、もしくは識別出来るようになる学習をする時にその学習元のDataのSizeを調整する事はあまりしないはずです。
ので当然、AIの学習においても色々なSizeのImageを直接学習させた方が効率が良いのではないかと言う感想が出て来ます。
昔はDataを保持するMemoryの確保は非常に重要な問題で、Memoryを効率的に使用する事は必須の事でした。
しかし今は別にそんな事はありません。DataのSizeをバラバラにした状態で学習する方法もあったら良い気がします。
<<RandomResizedCrop explanation>>
Blogによるとこの節では「RandomResizedCrop()関数を使用するとImageを少しだけ変更する事が可能である」と説明されているそうです。
このまとめでは、この関数を使用する事によってどんな風にAIの学習の効率が上がるのかについての具体的な説明が無いですね。
Lectureをもう一回見てLectureではどんな説明をしているのか確認します。
見ました。
ここではBlogにまとめた通りで、この関数を使用する事によってどんな風にAIの学習の効率が上がるのかについての具体的な説明は無かったです。
それは次の節である<Data augmentation>で説明するみたいです。
<<Data augmentation>>
あれ、BlogにはRandomResizedCrop()関数を使用して学習に使用するImageを一寸だけ変更する事をData Augmentationと呼ぶとしか書いていません。
Lectureでもそうだったのか確認します。
うーん。
どんな風にAIの学習の効率が上がるのかについての具体的な説明はありませんでした。
<<Question: Does fastai's data augmentation copy the image multiple times?>>
ここのBlogのまとめは、よく分からないと言いつつかなり秀逸な事が書かれていたので、ここでもその内容を繰り返して書いておく事にします。
まず以下の質問がありました。
「data augmentationの実装に対しての質問で、これらの画像は元の画像をCopyして作成しているのか」
それに対して私はこの質問の目的が
- 元の画像を編集する事によって計算Costが余計にかかる事を気にしてCopyしているのかを聞いてるのか
- 元の画像を編集する事は著作権違反ではないのか?という意味で質問しているのかもしれない
のどちらかなのかが分からない。
よってその質問の回答である
「Copyする時に条件を少しだけ変更する事で一寸だけ違うImageをCopyしている。」
の回答のどこが大切なのかが不明である。と書いています。
これは今、もう一回考えてみましょう。
もし質問の目的が「元の画像を編集する事によって計算Costが余計にかかる事」だった場合は、この回答による答えは、計算Costは余計にかかる事になる。となります。
ただどれくらい余計にかかるのかは不明です。僅かかもしれません。
後生成したImageをどこに保持するかによっても計算Costが変化するはずです。VRAMでそのDataを保持するのかどうかも大きな問題です。
つまりこの回答だけでは何とも言えないです。
次に「元の画像を編集する事は著作権違反ではないのか?」が質問の意図であった場合です。
これは「Copyする時に条件を少しだけ変更する事で一寸だけ違うImageをCopyしている。」という行為が著作権違反にあたるのかどうかが問題になります。
これに関してはよく分かりません。
個人的には著作権違反にはならないと思います。
学習に著作物を使用するのは著作権の範囲外ですので。
ではここまで考察した上でもう一回Lectureを見てみましょう。
うーん。
分からん。
この回答を聞くとCopyする事は明らかに悪い事で、Copyはしてはいない。と回答する事でその悪い事はしていません。と強力に主張しているのは理解出来ます。
しかしCopyする事の何が悪いのかについては一般常識化しているらしくその説明はしていません。
<<Training a model so you can clean your data>>
ここで実際に熊のDataからAIをTrainingしました。
一応Lectureも見て確認しましたがそれだけでした。
<<Confusion matrix explanation>>
来ました。
ここでConfusion Matrixを説明しています。

これを作る事で、どのPredictionに間違いがあるのかを可視化して把握する事が出来ます。
Blogではこの図の説明はあまりしていません。
Lectureも見直しました。
Lectureでは以下の解説をしていました。
- Confusion Matrixが役に立つのはLabelがClassificationの場合だけ。
- 具体的にBlack Bearだと予測したらGrizzly Bearだった場合が2つあり、その逆も2つありました。しかしTeddy Bearと間違えた場合は0だった。
- 失敗を分類する事でAIはどの予測が苦手なのかが判明する
ここで2024-09-08のBlogは終わっていました。
<<plot_top_losses explanation>>
前回、中途半端で終わってしまったConfusion Matrixの説明からやるのかと思ったら、次の節から始めていました。
plot_top_losses()関数についての解説です。
Lossが最も高いImageを返すみたいですね。とだけ書かれていました。
これは間違ってはいないはずです。
Lectureを見て確認します。
Lectureではもう少し詳しい解説がされていました。

ここで表示される結果がLossが最も高かった結果です。
2つ重要なPointを述べていました。
一つ目はProbabilityが高いにも関わらず間違った予測をした場合と、予測は合っていましたがProbabilityが低い場合がLossが高い結果として表示されている事です。
二つ目はImageで確認するとLabelが間違っている場合もあるという事です。
後、Blogでは「Lossについての細かい定義なんかも説明していましたが、腑に落ちる説明では無かったです。」と書いていましたが、このLossに関しての説明は理解しました。
Lectureでは「Lossは作成したModelがどれぐらい優れているかを示す基準である。」と言ってるだけでした。
<<ImageClassifierCleaner demonstration>>
ImageClassifierCleaner()関数を使用して間違ったDataを消去する方法を説明しています。
Blogの解釈によるImageClassifierCleaner()関数の使用方法では、一個ずつImageを確認しなければならない。と書かれています。
これは正しいですが、Imageが表示される順番をLossが高い順とかに変更は出来ないんでしょうか?
Lectureで確認します。
表示されるImageの順番はLossによって決まると言っていました。
それなら最初の10個ぐらい確認すれば良いのか。
<<Putting your model into production>>
やっとここから前回作成したModelを使用してProduction(製品)を作成します。
HuggingFace Spacesの紹介がここから始まります。
BlogではこのHuggingFace Spacesは先程勉強したCleanを行うために使用すると書いてありました。
これは今なら間違っている事が分かります。
でも今でも一寸分からない部分もあります。それはHuggingFace SpacesでAIのWebsiteを全部作成出来るのかどうかです。
多分出来るはずです。
更にこの部分は教科書では説明してない事も書いてありました。
これは重要な情報です。
でHuggingFace Spacesを使用するに当たってSpace SDKを選択する必要があるんですが、そこではStreamlit、Gradio、そしてStaticがあるんですがその中からGradioを選択していました。
このGradioが何をするためのSDKなのかが不明です。
これはCopilotに聞いてみます。
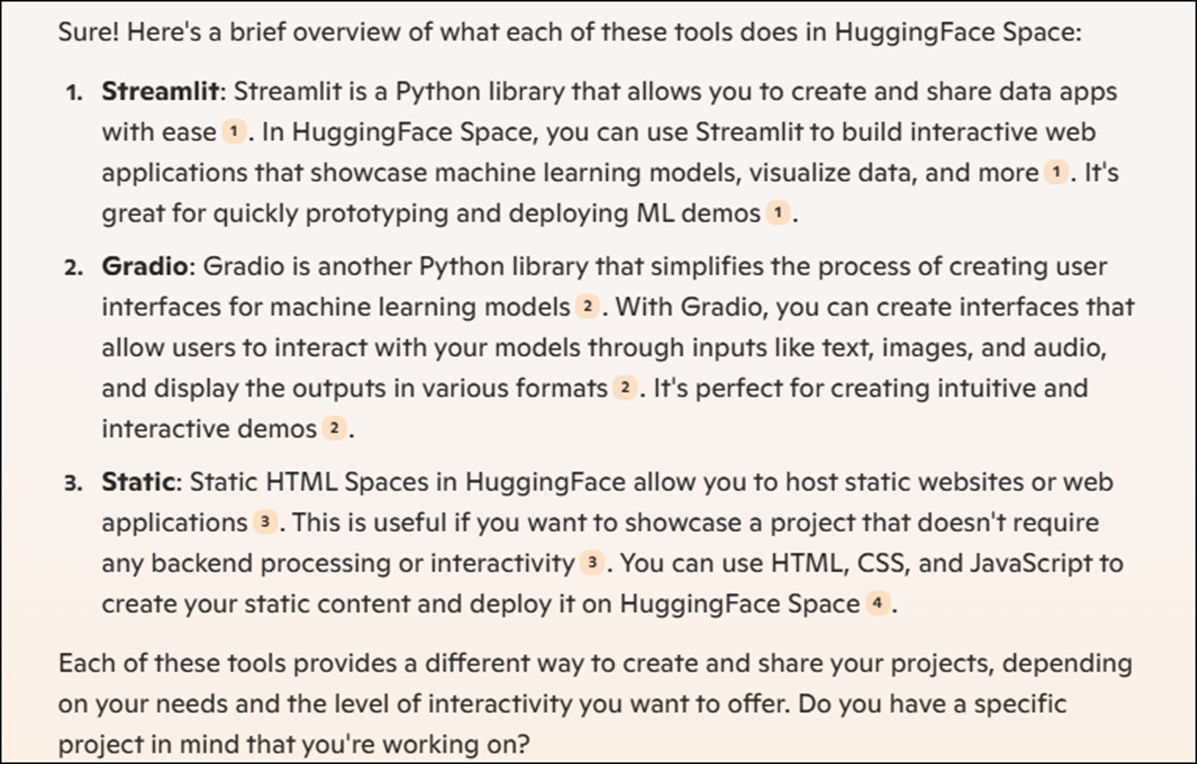
だそうです。
うーん。
成程。全部WebのUIを作成するためのSDKですね。
この説明を読むとStreamlit とGradioはともにMachine Learning関連のWebを作成するのが目的でGradioはStreamlitと比較すると使用が簡単なのが特徴のようです。
Lectureも見直します。
特に追加する情報は無かったです。
<<Git & Github desktop>>
BlogではGitの使い方が説明されている。としか書かれていません。
もう一回Lectureを見てまとめ直します。
GitHub Desktopを使用したら便利だよ。としか言ってなかったです。
<<For Windows users>>
WindowsからGitHubをCommandから使用する方法を説明しています。
Windows TerminalをInstallします。
PowerShellからWSLをInstallします。
ここでWindows TerminalからWSLつまりUbuntuを開いてそこからGitHubのCloneを得るためのCommandを実行しているはずなんですが、その部分の説明はBlogではありません。
Lectureで確認します。
説明してません。
いきなり以下の画面から始まっています。

(base)と表示されていますが、これって何なんでしょう?
Copilotに質問したら教えてくれました。
2つ方法があるそうです。
一つ目ですが以下の方法です。

次がUbuntuを使用する方法です。

更にPowerShellでやる方法も教えてくれました。

はい。
どれかでやります。
Installが完成した後です。
以下のCommandを実行します。

VS Codeが開きます。
App.pyを開きます。

ここにはGradioを使用してUIを表示するための実装が書かれています。
以下のIconを押します。

すると以下の画面に切り替わるのでMessageにCommentを書いてCheckのIconを押します。

これでHugging Face SpaceのWebpageが更新されるそうです。
以下のWebsiteが出来てました。

うーん。
Gitの方のどこかでHugging Face Spaceの自分のAccountを指定する必要がありそうですけど、その辺の説明はないですね。
これで2024-09-15のBlogはお終いです。
一応、Lectureの方も見直します。
Lectureを見たらCodeでVS Codeを開きそこにApp.py Fileを自分で作成して更にそこに以下のCodeを実装しろって言ってました。

そうだったのか。
まあこれは実際に実装する時に詳しく勉強する事になるでしょう。
Lectureを見直しましたがHugging Face Spaceの自分のAccountを指定する箇所はなかったです。
ここで勉強する時間が無くなってしまいました。
残りは来週やる事にします。
4. Nvidia Omniverseの勉強
今週は2 - Importing URDF to NVIDIA Isaac Sim - MuSHR RC Car - Ackermann Tutorial[4]におけるXacro FileからURDFに変換する手順を復習します。
4.1 Blogから2 - Importing URDF to NVIDIA Isaac Sim - MuSHR RC Car - Ackermann Tutorial[4]を復習する
2024-09-23のBlogで勉強していました。
以下のTerminalを開き

MkdirでDirectoryを作成しています。
このTerminalがなんのTerminalが不明ですが私が試す時はUbuntuでやります。
-pはどんな意味なんでしょう?
一応、Copilotに質問してみます。

作成したsrcのFolderに移動しました。

そしてGitのCloneを作成しました。
次です。

これはVS Codeぼいですが、どうやって開いたのかはBlogには書かれていません。
Tutorialを見直します。
VS Codeって言っていました。
ここからXacroのあるFileの場所が判明したので以下のCommandでXacroの場所に移動しています。

以下のCommand
cd mushr/mushr_description/robots/
でXacroのあるDirectoryに移動しました。
次に以下のCommandでXacro FileをURDFに変換しました。

成程。
Rosrunを使用しているという事はROSは既にInstallされているという事です。
私の場合はROSをInstallしたので以下のCommandを実行する必要があります。
ros2 run xacro xacro --inorder -o mushr_nano.urdf mushr_nano.urdf.xacro
ここで一つ疑問が出て来ます。
2024-11-24のBlogではROS2を実行する前に以下のCommandを実行する必要がありました。

これってROSを実行する度に毎回打つ必要があると思っていたんですが違うんでしょうか?
Copilotに聞いてみました。

これを読んだ限りでは先程のCommandは必要のようです。
大体理解しました。
次節にどうやってXacro FileからURDFを作成するかの手順をまとめます。
4.2 Xacro FileからURDFを作成する手順
まずWindows TerminalからUbuntuを開きます。
このTutorialを実行するためのFolderを作成します。
Tutorialでは以下のFolderを生成しています。

同じようにします。
mkdir -p mushr_tutorial_ws/src
と打ちます。
ここでTerminalがSrcのFolder内に移動してない場合はCdを使用してSrcのFolderに移動します。
SrcのFolderに移動したらGitからCloneを生成します。
あ、このGitのURLがあるGithubのSiteのAddressが分かりません。
これは後で調べます。
<<追記>>
調べました。
MuSHRでした。

をClickします。
以下のPageに移動します。

このCodeを開くと以下のURLが載っていました。
https://github.com/prl-mushr/mushr.git
このURLでこのgitのCloneが生成出来るはずです。
<<>>
Cloneに成功したらVS Codeを開いてMushrのCodeを確認します。
Commandは
code .
です。
Copilotによると

最後のPeriodはこのFile上でVS Codeを開けと言う意味だそうです。
これは今試してみます。
以下のように打ってみました。

このHostを信用するのかとか色々聞いてきましたが全部Yesと答えると

Visual Studio Codeが開きました。
しかもこのFolder内で開いていました。
確認出来ました。
Xacro FileがあるFolderに移動します。
Mushr Folderに移動しMusher_description Folderに移動しRobots Folderに移動すれば良いはずです。
Commandは
cd mushr/mushr_description/robots
で行けるでしょう。
RobotsのFolderに移動したらLsを使用してFileを確認します。
以下のFileが表示されるはずです。

ここまではまあ、単に手順をまとめただけですが、ここからが重要です。
このFolder内でROS2を起動してXacro FileからURDFを作成しますが、まずROS2を起動させるCommandを打つ必要があります。
source /opt/ros/jazzy/setup.bash
そして最後にXacro FileからURDFを作成する以下のCommandを実行します。
ros2 run xacro xacro --inorder -o mushr_nano.urdf mushr_nano.urdf.xacro
あれ?
このCommandだとmushr_nano.urdf.xacroしかURDFに変換しないんじゃ?
うーん。
まあいいや。
これでXacroからURDFに変換出来るはずです。
5. Gaeaの勉強
5.1 PowerPointの作成
今週はHeightmapの作成方法についてです。

今週のLectureの内容です。

全体の工程の中からどの辺を勉強するのかを解説しました。

3つの工程の2番目の工程である「色を追加」は勉強しない事を繰り返しになりますが、説明しました。

Fabについての解説です。
これは12月が終わるまではずっと続けます。

MegascanのAssetの数を見直したら18000ありました。17000じゃなかったです。

MegascanのWebsiteでも同様にOne Clickで全てのAssetがもらえるようになった事について解説しています。
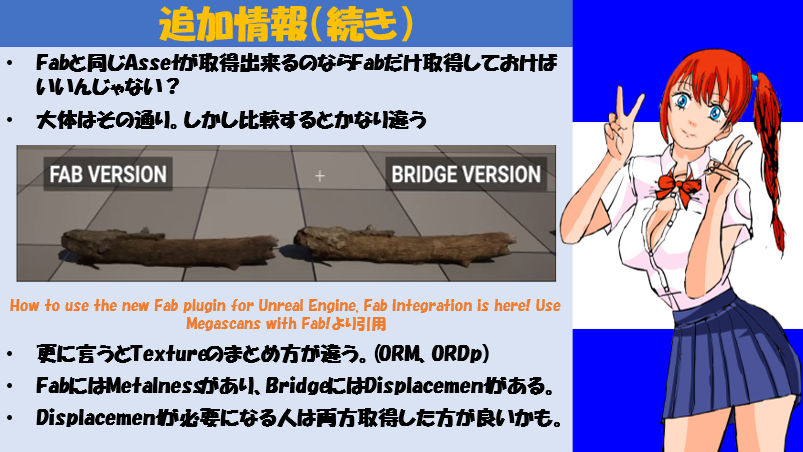
同じAssetでもFabとMegascanでは微妙に違う事について解説しています。

2週間に一度、公開される期限付きの無料Assetについての紹介です。

これも無料で購入する事ができますが、2種類のLicenseがあり両方のLicenseを購入するためには2回、購入する必要がある事を説明しています。

ここからHeightmapのBuildのやり方を説明しています。
Unrealノードを使用したHeightmapのBuildの方法を説明しています。

Unrealノードの使用方法について解説しています。

HeightmapのSaveする場所を指定する方法を説明しています。

続きです。

これも続きです。

Buildを押してHeightmapを生成します。

Projectを一回もSaveした事が無い場合は、ここでProjectのSaveする場所を聞いてきます。
それを説明しています。

生成されたHeightmapを示しています。

まとめです。
5.2 Gaea2における実習の撮影
今週はGaea2からFileのSaveする場所を指定したり、Exploreから生成されたHeightmapのあるFolderを開いたりしました。
Exploreの表示から個人情報が漏れないか心配で色々モザイクをかけました。
TimestampにもMosaicをかけるべきか悩んでいます。
6. Houdiniの勉強
今週も以下の2つを勉強していきます。
- VEX Isn't Scaryの勉強
- 2024-08-04のBlogの勉強の続き
6.1 VEX Isn't Scaryの勉強
6.1.1 VEX Isn't Scary Part 6 Clarification [5]を実装する
先週勉強したVEX Isn't Scary Part 6 Clarification [5]を実装していきます。
<Conditional Logic and Variables>
先週のBlogには以下の内容しかまとめられていませんでした。

これだけではどんな結果になったらColorのScopeがIf節内で完結しているのかが分かりません。
以下のようなNodeを組んでテストします。

ここのAttribwrangleノードに先週のBlogでまとめた実装を追加すると

Errorになりました。
それはそうです。
それが説明したかったのか。
納得。
以下のように実装を書き換えました。
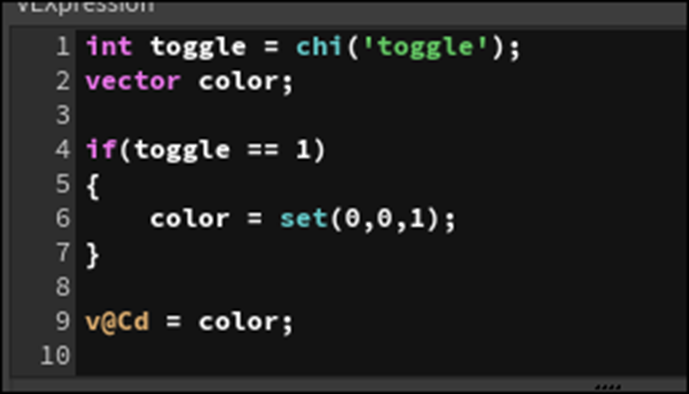
Errorが消えました。
更にToggleの値を1に変更すると

Pointの色が青くなりました。

<Detail Attributes And Else-if>
先週のBlogではDetail AttributesとPoint Attributeの優先順位について以下のように解説しています。
- Detail Attributeの値があるだけの場合は、その値をPointのAttributeとしても使用します。
- 同じ名称でDetail AttributeとPoint Attributeの2つがある場合はPoint Attributeの値が使用されます。
しかしこれを確認するための実験方法はまとめられていません。
ああ、分かった。
Attribute WangleノードのRun Overの値をDetail(only once)に変更します。

Geometry Spreadsheetで確認すると
Pointの欄にはAttribute Cdはありませんが、

Detailの欄にはAttribute Cdがあります。

これでAttribute CdはDetail Attributeになりました。
しかしToggleの値を1にすると

以下のようにPointの色が青くなりました。

これで最初の「Detail Attributeの値があるだけの場合は、その値をPointのAttributeとしても使用します。」は証明されました。
次に以下のようにAttribute Wangleノードを更に追加し

そこで以下の実装を行います。

Point AttributeであるCdを新たに指定しました。
Geometry Spreadsheetを開いて確認すると

確かにPoint Attributeの項にCdの値が表示されています。
しかもDetail Attributeの欄にもCdがあります。

Cdのそれぞれの値ですが、Detail Attributeは青で、Point Attributeは緑を示す値が指定されています。
結果を見ると

Point Attributeの値である緑が表示されています。
これは先週のBlogに書かれた「同じ名称でDetail AttributeとPoint Attributeの2つがある場合はPoint Attributeの値が使用されます。」と同じ結果になった言えます。
うーん。
言えるのか。
単にAttribute Wangleノードの順番のせいかもしれません。
Nodeの順番を入れ替えてみました。

結果です。

緑のままでした。
これなら「同じ名称でDetail AttributeとPoint Attributeの2つがある場合はPoint Attributeの値が使用されます。」が言えます。
先週のBlogでは、更にDetailはどんな時に使用すべきなのかについて例を使用して解説しています。
例で使用されているCodeを実装します。

当然Run Overの設定はDetail(only once)です。

Geometry Spreadsheetを見ると
Detailの項にSeason Attributeが生成されています。

はい。
ここでこのDetail Attributeの値をRun Overの値がPointにセットされたAttribute Wrangleノードから呼び出す方法が説明されています。

試してみます。

Geometry Spreadsheetで確認します。

あれ?
値が空白になっています。
色々調べたらAttribute Wrangle1ノード内の実装で以下のように書いてありました。

SeasonがSesasonになっています。
直しました。

Attribute Wrangle2ノードのGeometry Spreadsheetの結果です。

Summerになっています。
更に以下の実装をAttribute Wrangle2ノードに追加しました。

Attribute Wrangle1ノードのSeasonの値を変更すると

以下のようにPointの色が緑になったりOrangeになったりしました。


はい。
やっとこれが出来ました。
単なるTypoでこんなに時間を取られてしまったのはかなりショックです。
先週のBlogでは次に以下の内容が書かれていました。

試してみます。
先程の実装を以下のように組み直してみました。

結果です。
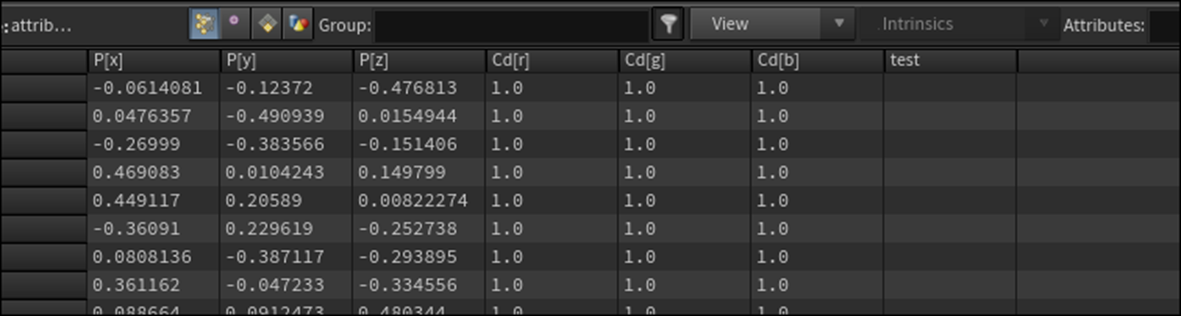
Attribute Wrangle1ノードで作成したDetail AttributeであるSeasonの値が取得出来ていません。
出来ないじゃん。
うーん。
Tutorialを見直したら以下のように実装していました。

つまりAttribute Wrangle1ノードの後で、全てのPointを消し、Add1ノードとMergeノードを使用してPointを一個だけ追加します。
この場合でもその一個のPointはAttribute Wrangle1ノードにあるSeasonの値で色が変化しています。
はい。
これを試します。
以下の実装を組みました。

結果です。


はい。
独立していたAddノードで追加したPointにもAttribute Wrangle1ノードで指定したSeasonの値で色が変化しています。
出来ました。
出来たは出来たんですが、思っているより2倍ぐらい大変でした。
まずDeleteノードですが、

ただ繋げただけではPointを消してくれません。

Entityの値をPointに変更して

NumberにあるPatternの値を*に変更する必要があります。
Entityの値をPointに変更するのは理解出来ますが、Patternの値を*にする意味はよく分かりません。
更にAddノードもそのまま配置しただけではPointを生成しません。
以下のNumber of Pointsの値を1に変更したら

Pointを生成しました。
<Common Attributes and Indexing Variables>
Defaultで機能が決まっているAttributeの事をCommon Attributeと呼ぶ事について解説してます。
更に何個かの基礎的なCommon Attributeについて解説しています。
それぞれのCommon Attributeを試してみます。
<<v@v>>

Velocityを指定するCommon Attributeです。

このAttributeはVelocityの初期値を指定したり、Motion Blurを追加する時に使用するそうです。
Motion Blurを試してみました。

先週のBlogを読んだら大体出来ましたが一か所だけ分からない箇所がありました。
以下のButtonの場所です。

Preview画面のTabからRender Viewを選択する必要があります。

それだけです。
<<f@pscale>>

これは以下の実装で試してみます。

結果です。

それぞれのBoxの大きさがpscaleの値のせいでRandum化しています。
<<v@scale>>

以下の実装をしました。

結果です。

これは@pscaleのVector版というだけでした。
<<v@N>>

Normalを指定するCommon Attributeです。
以下の実装でTestします。

以下のIconをEnableしてNormalを表示します。

これが

以下の実装を追加した事で

以下のように変化しました。

<<Indexing Variables>>

それぞれのPointを識別するためにHoudiniが生成するCommon Attribute達を総称してIndexing Variablesと呼ぶそうです。
ここではi@ptnumのPointの数が変更されるとi@ptnumの値も変化するという特長が説明されています。
まずこれを確認します。
Blogにまとめた例を試しましたがこれが正しいのか分かりません。
Tutorialを見直したら正しいやり方が分かりました。
以下のように実装したら
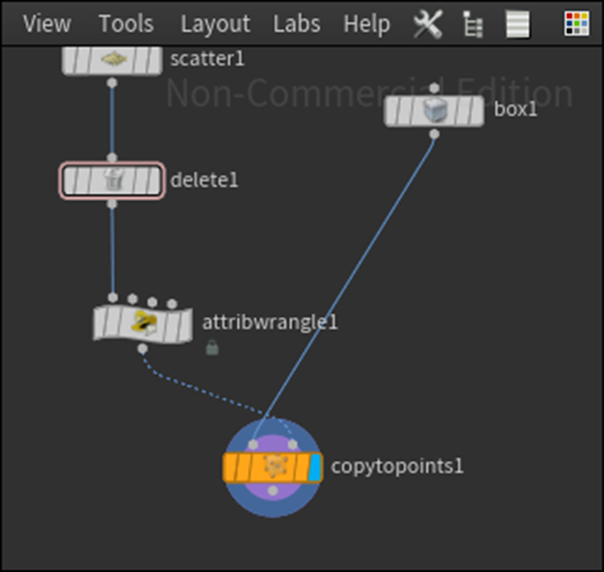
DeleteノードのSelect_of_の値を変更します。

するとPointの数が変化します。
その結果、@Ptnumの値も変化するのでBoxのSizeが変化します。


これでPointの数が変化すると@ptnumの値も変化するという事が証明出来たって事みたいです。
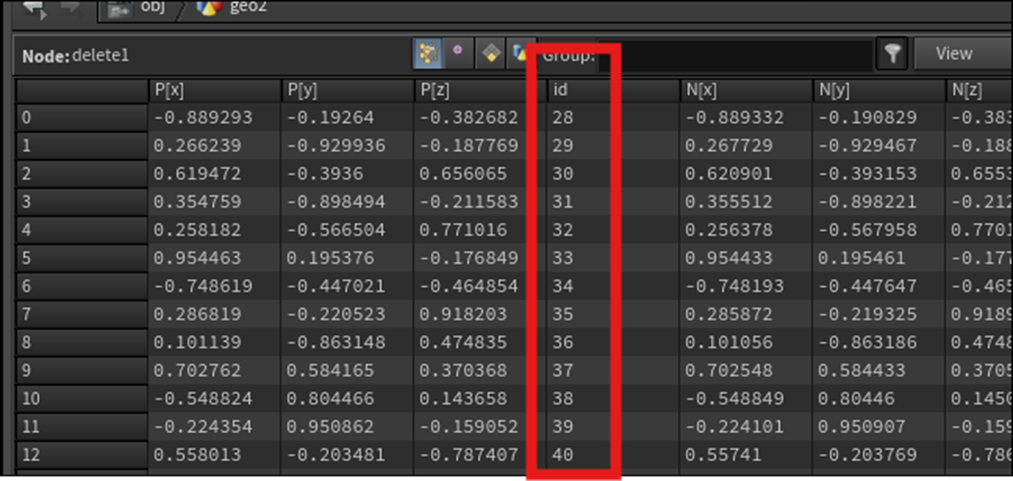
<<i@id>>

Pointの数が変化してもそれぞれのPointで変化しないIndexを作成するためにこのAttributeを使用するそうです。
以下のように実装します。

DeleteノードのSelect_of_の値を以下のように変化させると

Idの値は変化していません。
以上です。
6.2 「2024-08-04のBlogの勉強」の続き
今週もこれはお休みします。
もう疲れました。
7. VFXの勉強
7.1 「Houdini is HIP - Part 4: Rendering [5]の最後の10分を実装する」を勉強する
最後の10分を勉強します。
<21:25 Revisiting the Coconut Generator>
Coconut GeneratorにあるScatter1ノードのDensity Scaleの値を1000に増やしました。

こういう細かい事はそんなに重要じゃないかもしれませんが、一応記録に残しました。
次にAttribcreate1ノードにある

Valueの値を0.013に変更しました。

結果です。

Coconutの破片のSizeが小さくなりました。
近づいて見ると以下のようにCoconutの破片がDonutから浮いています。

これを直すために以下の変更を行います。
Attribnoise1ノードの

Amplitudeの値を0.01に下げ
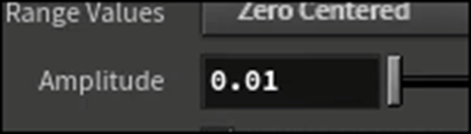
Element Sizeの値を0.025に変更します。

結果です。

Coconutの破片をもっとばらつかせます。
以下の場所にAttribute Noiseノードを追加します。

そしてAttribute NoiseノードのAttribute Namesの値をFloat、Densityに変更します。

そしてすぐ下のScatter1ノードを選択し

Density AttributeをEnableし値にdensityをセットします。

このDensityの割合を可視化します。
以下のIconをClickすると

以下のように色でDensityの割合が表示されます。

Attribute NoiseノードのElement Sizeの値を0.48に下げました。

Densityが変化しました。

ちなみに寒い色程Densityが低くなるそうです。
Attribute NoiseノードにあるEnable Remap RampをOnにします。

Rampが表示されました。
Rampの設定を以下のように変えて

以下のようにDensityにばらつきを持たせました。

ScatterノードにおけるDensityの表示です。

綺麗なのでのせました。
更にAttribute NoiseノードのOffsetの値をいじって微調整していました。

最終結果です。

<25:10 Adding other Materials>
今度はCoconut用のMaterialを作成します。
Material Networkノードを開いて
以下に示したCoconut用のPrincipled Shaderノードを追加します。

Principled Shaderノードの設定を変更します。
まずBase Colorの設定です。

色を変更し、Use Point ColorをDisableしました。
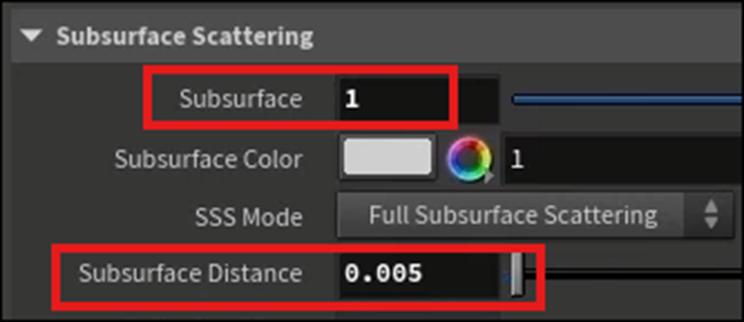
SpecularのRoughnessの値を上げました。

更にSubsurfaceの値を以下のように変更しました。
Object Layerに戻りCoconut Generatorノードを選択し
RenderのMaterialに今作成したPrinciple Shaderノードをセットします。

Karma Renderingで見た結果です。

この後Cameraの位置を変更したりFloorを追加したりしています。
Floorの作成ですが、
まずFloor用のPrincipled Shaderノードを追加しました。

Basicの設定ですが以下のようにしていました。

何とここでFloor用のPrincipled ShaderノードをDragして直接ViewportにあるFloorにDropしました。

これでもPrincipled ShaderをFloorにセット出来るんでしょうか?

セットされていました。
Karma Renderingから見た結果です。

<27:10 Messing Around>
ここではArea Lightなどの値をいじって微調整しているだけでした。
<28:45 Rendering an Image Out>
ImageのRenderの仕方ですが、Karmaノードにある以下のRender to DiskをClickします。

Clickしても何も起きません。
しかし以下のRenderからSchedulerを選択し

以下のBoxを開くと

今Renderingされている事が分かります。
しばらく待つとRenderingが完成します。
よし出来たImageを見ようとすると何と、どこにSaveされたのかが分かりません。
Karma Renderingノードの以下の場所を見ると

どこにSaveされたのかが分かります。
でもこのPath読めません。
TutorialでこのPathの読み方を説明していました。
まず$HIPですが、これはこのHoudiniのProjectがSaveされている場所を指すそうです。

次のRenderはRender Fileの事です。
その次の$HIPNAMEはこのProjectの名前だそうです。
その次の$OSはRenderingに使用したNodeの名前だそうです。
最後の$F4はFrame Numberだそうです。Animationを作成する時はこの数字が増えるはずです。
はい。
理解出来ました。
<31:40 Outro>
特になし。
以上でした。実装は来週やる事にします。
8. DirectX12の勉強
8.1 Lötwig Fusel氏のD3D12 Beginners Tutorial [D3D12Ez]を勉強する
8.1.1 BackBuffer as ID3D12Resource | D3D12 Beginners Tutorial [D3D12Ez] [6]の次の10分を勉強する
残りを勉強します。
作成したBufferをReleaseするための実装をShutdown()関数に追加します。

ここで実行してTestしています。
WindowのSizeを変更したりFullscreenにしたり、F11を押して全画面表示にしたり、元に戻したりしています。
何の問題もありません。
しかしTutorialによるとこれでも完成では無くて、この後にある問題が発生するそうです。
Outputを見ると以下のErrorが表示されています。

このError Messageは、実際はBufferのSizeを変更する前に、このBufferの全てのReferenceがDeleteされていない事を示しているそうです。
ふーん。
更にTutorialではGPUではCPUのようにmallocのような機能がないので、BufferのSizeが変わった時にMemoryのSizeをReallocateする事が出来ないからだ。と説明していました。
あれ?
こういう事こそ大事なのになんで今までこういう話を素通りして勉強して来ちゃったの?
というか、なんか突然目が覚めた感じがします。
こういう事が大事である事に突然気が付き始めました。
ではBufferをReleaseするための実装を追加します。

うーん。
ここはBufferにReferenceしているすべてのObjectをDeleteするための実装を追加するんじゃないの?
と思ったら
どうも以下のVariableがArrayであるからBufferにReferenceしている事になってるみたいです。

こいつをReleaseすれば結果的にはBufferにReferenceしているすべてのObjectをDeleteする事になる訳です。
はい。
GetBuffer()関数の実装です。

更に以下の部分を書き換えて

GetBuffer()関数を使用しました。

ここは先週のBlogでSample Codeと実装が違うと書いていた部分です。
これでSample Codeと同じ実装になりました。
更にReleaseBuffers()関数の実装も追加しました。

このReleaseBuffers()関数は以下の場所に使用しています。

これで、BufferをReleaseするための実装を追加するための関数が揃いました。
以下のように追加します。

ああ、分かった。
最初の部分の実装の変更は単にCodeが読み易いように整理してただけだったんだ。
ようはGetBuffers()関数の機能も、ReleaseBuffers()関数の機能も既に実装はされていたんだけど、一回しか使用しないからあえて関数にはしてなかったんです。
それが今回BufferをResizeする時に、BufferをReleaseしたりGetしたりする必要が出て来たので、関数にする事でCodeを読み易くしたわけです。
はい。
理解しました。
この後、テストしていますが、もうErrorは表示されなくなりました。
実装は来週やります。今週はここまです。
9.2 「DirectX 12の魔導書」を勉強する
9.2.1「5.7.2 Shader Resource Viewを作る」を実装する
以下の部分の実装をSample Codeからコピペしました。

更に
CreateShaderResourceView ()関数を使用してShader Resource Viewを作成する以下の実装を追加しました。

先週のBlogを読むと

とかかれています。
のでShader Resource Viewが実際にこれで作成されているかの確認は出来ないのでDebugで確認はしません。
以上です。
9. 参照(Reference)
[1] Procedural Minds. (2024, July 28). Get started with PCG 5.4 by creating a full building | UE 5.4 p1 [Video]. YouTube. https://www.youtube.com/watch?v=oYNA24tcYc0
[2] NumenBrothers. (2023, September 23). How to Edit Mannequin and/or Metahuman Animations directly in Sequencer [Video]. YouTube. https://www.youtube.com/watch?v=GlASFzRdR6M
[3] Jeremy Howard. (2022, July 21). Lesson 2: Practical Deep Learning for Coders 2022 [Video]. YouTube. https://www.youtube.com/watch?v=F4tvM4Vb3A0
[4] Berk Tepebağ. (2024, August 20). 2 - Importing URDF to NVIDIA Isaac SIM - MUSHR RC Car - Ackermann Tutorial [Video]. YouTube. https://www.youtube.com/watch?v=fbgJAwI5iYY
[5] Nine Between. (2023, March 30). Houdini is HIP - Part 4: Rendering [Video]. YouTube. https://www.youtube.com/watch?v=L3SUQMKGtb8
[6] Lötwig Fusel. (2023, July 6). BackBuffer as ID3D12Resource | D3D12 Beginners Tutorial [D3D12EZ] [Video]. YouTube. https://www.youtube.com/watch?v=ExMykz6lnXg